
Flaky Tests, Courtesy of AI
When AI is writing tests in agentic mode, it's crucial to monitor its output.
Sometimes, it uses tricks to pass the tests or creates unnecessary tests.
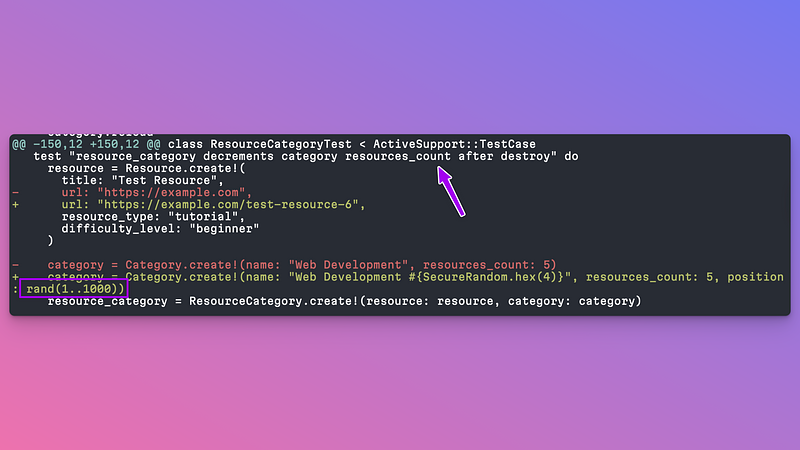
For example, consider this diff that has at least two issues:
1. The test is unnecessary for a medium-risk, medium-impact feature. It merely checks that the counter cache in Rails functions correctly. This test was written in an earlier iteration that I haven't reviewed yet to remove it.
- The Category model has the following constraint:
index_categories_on_position_and_parent_id (position, parent_id) UNIQUE
Notice how it added a position: rand(1..1000) to make some tests to
pass because they lacked the position?
This approach is just inviting flaky tests!
I added this to my Flakiness section:
- Use consistent data across tests to avoid flakiness. Prefer existing fixtures instead of generating data randomly. - Do not use `rand` or anything similar when generating data for tests. - Use `travel_to` for all time-sensitive tests (assert time or need time to make the test work) - Use `.sort` when the results are not guaranteed to be in a specific order.