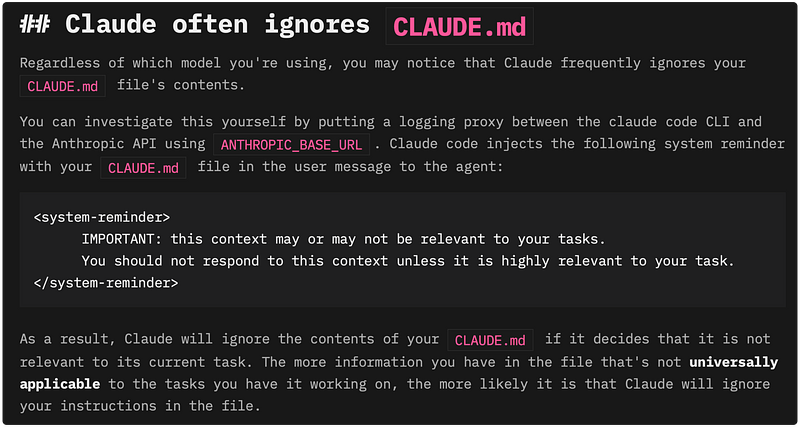
Using both Codex and Claude Code CLI to manage JIRA tickets (previously created from a requirements doc via Claude Code), I noticed something interesting about how they behave in respecting with trimming or removing tickets.
When I already reviewed the tickets manually and have a clear plan for which ones to close or merge, Codex is the better choice. It executes quickly, responds briefly, and trusts my judgment.
Claude Code takes a different approach. It wants to discuss every detail, pushes back on closing tickets, questions whether overlapping tickets truly cover the same ground. This thoroughness is valuable when you are exploring or uncertain. But when you have already done the analysis, the back-and-forth becomes friction.
The lesson here is not that one tool is better than the other. It is about knowing when you need a tool that executes your decisions versus one that helps you think through them.
For ticket cleanup after manual review: use the tool that gets out of your way.
For initial ticket creation or complex refactoring: the questioning might save you from overlooking something important.
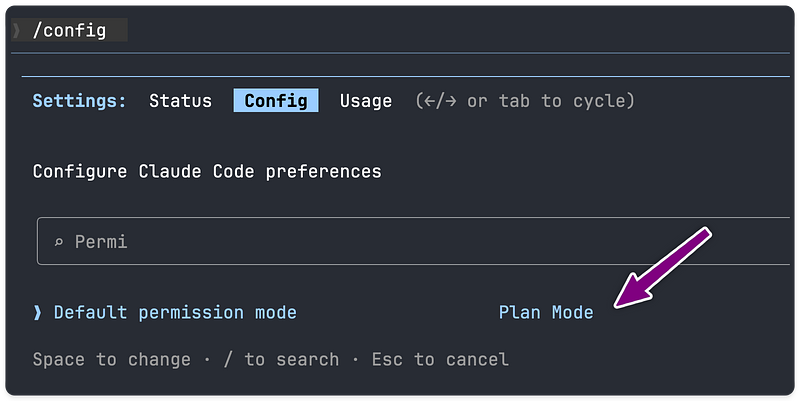
If you are usually first go to plan mode in Claude Code then you can set this mode as default in two ways:
You can run /config in your Claude Code session and then change the Default permission mode setting to Plan
Or you can edit your project settings or global settings at ~/.claude/settings.json to set this:
{ "permissions": { "defaultMode": "plan" } }
One more trick if you are in Claude Code settings is that you can change your plans directory to something that you might consider backup or even give it to a tool like qmd
Here are some notes about things I found interesting:
Study Design
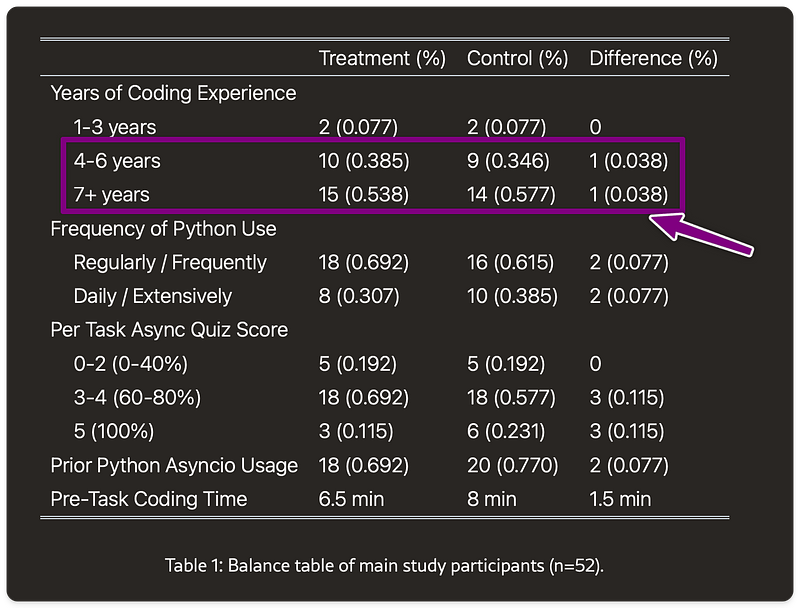
from the study: Balance table of main study participants
The researchers recruited 52 software engineers who were familiar with
Python and had experience using AI coding assistance tools. The task
involved learning Python asyncio, a library most participants hadn't
used before.
One interesting detail: the article describes participants as "mostly
junior" engineers, but when you look at the data, 55.8% have 7+ years of
coding experience and 36.5% have 4-6 years. This matters because the
findings apply more to experienced developers learning new concepts than
to absolute beginners.
ChatGPT agrees with me:
Response from ChatGPT when prompted to analyse the experience level of the participants in the study
The Core Finding: AI Doesn't Automatically Help
Learning
Developers who completed tasks without AI assistance scored higher on
comprehension tests. Using AI to generate code doesn't automatically
translate to understanding that code. This pattern held true across all
experience levels.
This matches my experience. When I use AI to generate code, unless I
make an intentional effort, I forget about that code very quickly. I
need to actively review the code, build a mental model, and trace
through the logic. Without that effort, I'm just watching the AI do
something and forget about it in a couple of hours.
Interesting Finding from the Pilot Study
Pilot Studies from the Anthropic Paper
During their pilot studies, the researchers discovered something telling
about how integrated AI has become in developer workflows. Even when
explicitly told not to use AI, 25-35% of participants still did.
This shows we reach for AI tools almost instinctively now. It's become a
default part of how many developers approach problems for a significant
part of the developers maybe.
What Actually Works: Two Practical Approaches
The study identified two approaches that worked well for both task
completion and comprehension:
Approach 1: Generation-Then-Comprehension: Generate code with AI, then
ask follow-up questions to understand what it did.
This group showed strong understanding in their quiz results. The key
was not just generating the code but actively engaging with it through
questions. They used AI as a learning tool, not just a code generator.
Approach 2: Hybrid Code-Explanation: Ask AI to generate code AND provide
explanations in the same response.
These participants spent more time reading, but developed better
understanding. The explanation forced them to engage with the concepts
rather than just copying the solution. The slower pace actually
contributed to better learning outcomes.
The Role of Debugging in Skill Formation
Encountering errors and debugging them plays a crucial role in skill
formation. The control group (no AI) hit errors, had to understand why
they happened, and learned through fixing them.
I think so far this process can't be fast-tracked. Debugging and
incidents are essential parts of becoming a better developer. These
experiences build the mental models you need to work effectively with
code.
AI can help you explore codebases and libraries during debugging, but it
shouldn't replace the process of understanding why something broke. In
my experience, throwing a zero-shot prompt at AI about an error is still
a dice roll. Sometimes it works, sometimes it doesn't.
Few-shot prompting with specific context, possible root causes, and
hints about the codebase helps. But you need to understand the problem
first to provide that context.
Implications for Engineering Leaders
If your developers rely heavily on AI for code generation, you need
processes that ensure they understand what's being generated.
During incidents or debugging sessions under pressure, developers need
the skills to validate and debug code quickly. If they've been primarily
copying AI-generated code without understanding it, they won't have
built those mental models.
This means thinking about: - How do we ensure learning happens
alongside productivity gains? - What code review processes help
developers understand AI-generated code? - How do we create space
for debugging and error-handling practice? - What onboarding
approaches help new developers build foundational skills?
Every week I curate what the Ruby community shares online and publish it
in Short Ruby
Newsletter.
In the last few months, I noticed a pattern that looks a lot like what
happened with TDD in the early days. The Ruby community is experimenting
again. Or at least this is how it feels to me. As a curator, I
spend time every week looking at what the Ruby community shares and
talks about. Let me share here few points I see:
Ruby code samples shared on social media are trending down. Posts about using AI and LLMs with Ruby are trending up.
Article about Ruby and Ruby content seems not to be so much affected by this. There is an increase in articles about using AI and Ruby but there are still good technical articles published.
A vocal part of the Ruby community is embracing AI and LLM tooling.
In general, the approach I see is not hyped-based, but there are many experiments on code quality and on how to use AI/LLMs to create better, faster products.
I am happy that the Ruby community is running with this. New gems are being published. New skills are being shared. This brings me back to the early days of the Ruby community when we experimented a lot with web frameworks and pushed the boundaries of what could be done.
Another example that I think shaped our ways of working and producing
software was TDD. It is maybe too early to tell if we are in the early
days of a Cambrian explosion of using AI/LLMs in daily coding life, but
could we be there as we were with TDD? Look around at testing frameworks
in other languages and see the impact RSpec had on them.
So the newsletter is reflecting this reality of our community and I try
as a curator to make sure that I include what the community talks about
every week.
The scope of the newsletter remains the same: primarily focused on code
samples, news, gem releases, articles, and videos. AI and LLM content is
there as it should be, showing where community interest lies.
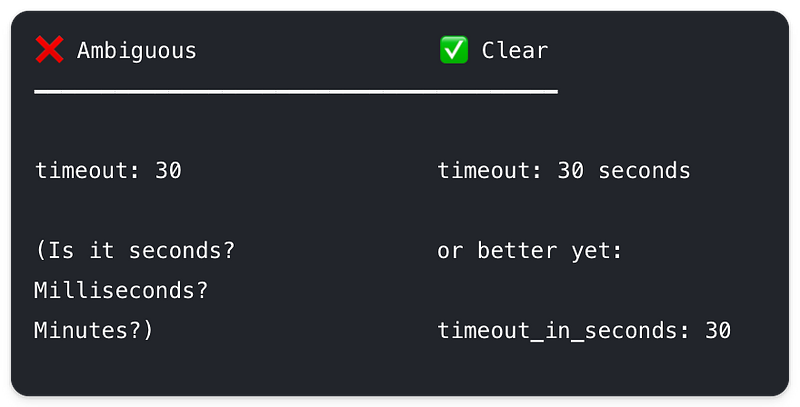
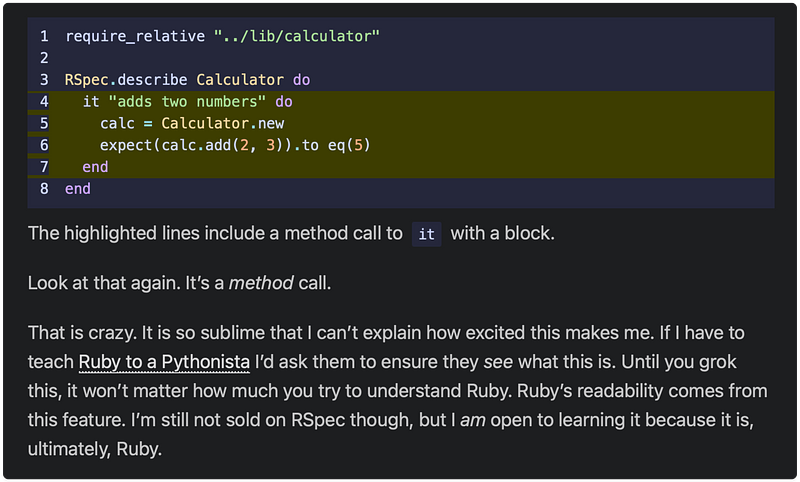
If you're writing API documentation, always specify units for duration
parameters.
Not just "timeout: 30" but "timeout: 30 seconds" or better yet
name the parameter if you can "timeout_in_seconds"
Example of good vs bad naming/description
This is even more important inside your own codebase. Make sure that
variables have proper names or descriptions or comments that specify the
unit of measurements moreso in case you are working with durations.
It matters for both developers and LLMs.
When the unit is ambiguous, the LLM guesses. Sometimes it guesses wrong.
Then developers debug code they didn't write, hunting for a bug that
shouldn't exist.
Clear documentation prevents bugs before they happen.
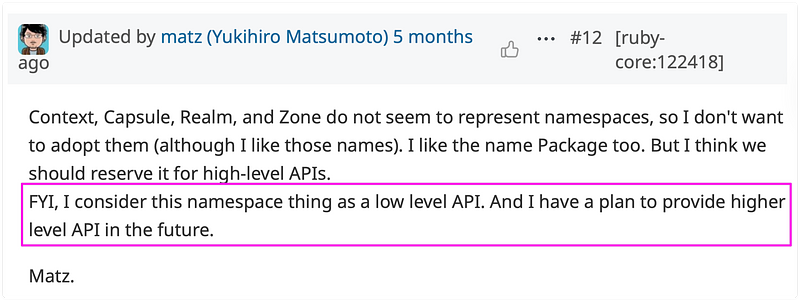
But what is interesting is also that Matz hinted that
this should be seen as a low-level API, with potential plans for a
higher-level API in the future. This development is exciting as it could
unlock new possibilities:
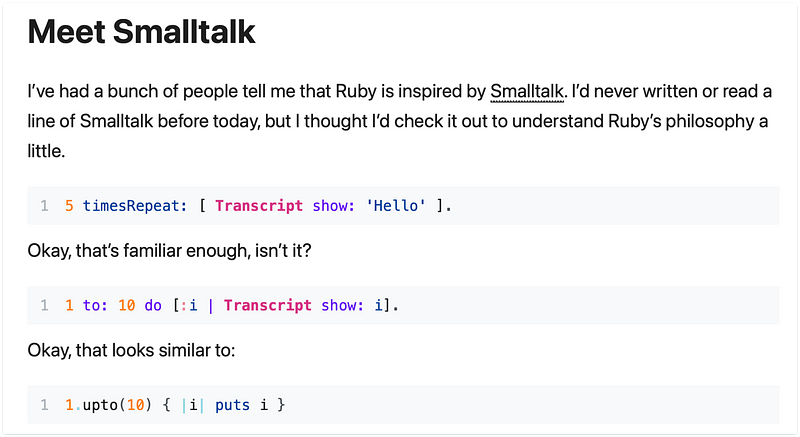
Noel Rappin continues his series of writing about Ruby and languages
that inspire it (if you have not read yet part 1 Ruby
And Its Neighbors: Perl) and this time it is about Smalltalk.
I liked very much this article as it goes into talking about the
innovations that Smalltalk brings to the table, and at the end I almost
felt sad that I never used Smalltalk professionally:
While Noel's article was writting from the persperctive of someone that
wrote Smalltalk professionally here Vinay explores the influence of
Smalltalk as someone who does not know Smalltalk. It is still refreshing
to see how the influence can be identified:
I'm certain, although I haven't had the time to develop a proper data
scraper to confirm, that Ruby articles are appearing more frequently on
the front page of Hacker News this year.
I'm specifically referring to technical articles.
Here's the latest example: Yesterday, there were two posts:
Joe Masilotti's article about "Ruby Already Solved My Problem" was on the front page and remained in the active list for a while.
I encourage everyone in the #Ruby community to move beyond the mindset
that "Ruby is declining." From what I observe, Ruby is growing in terms
of its presence in public discourse and the resources being created.
Let's discuss Ruby more openly. Yes, there are many other languages and
frameworks, both new and old.
I'm not a fan of criticizing others, so I believe we can talk about Ruby
without dissing other technologies. Engage with others and share what we
have.
Amabile, Teresa M. “A Model of Creativity and Innovation in
Organizations.” Research in Organizational Behavior 10, no. 10
(January 1, 1988): 123–67. https://ci.nii.ac.jp/naid/20000708825.
Here is how someone described where they were looking for inspiration:
in variations and deviations
Amabile, Teresa M. “A Model of Creativity and Innovation in Organizations.”
And then talking about their work environment they hint at something
that I also talked in the past: there has to be slack time (and not time
on Slack) during the work to be able to thinker with things without
having the pressure of always making something that is directly
productive:
Amabile, Teresa M. “A Model of Creativity and Innovation in Organizations.”